
When a custom software project fails, the damage spreads fast — across budgets, timelines, and executive trust. You approved the project in Q4, trusting a custom software development company that came across as confident and well-aligned with your goals. The proposal looked solid. The early demos were smooth. Then month five arrived, and everything quietly started falling apart — deadlines slipping, status updates getting vague, your project manager no longer getting straight answers from anyone on the vendor side.
Now it is month seven. You have burned $740,000. Nothing is in production. Your operations team is still working off spreadsheets. The vendor's last message was four days ago. Your CFO has a board presentation in three weeks, expecting a full progress update on the digital transformation initiative that has nothing to show for it.
This is not unusual. McKinsey research shows 17% of large IT projects threaten company survival. The Standish Group CHAOS Report puts on-time, on-budget delivery below 30%. Cost overruns routinely land 30 to 45 percent above original estimates before anyone calculates the full operational damage.
The question now is not how this happened. It is what you do next. This guide — built on real rescue engagements, not theory — gives you a structured answer to fixing a failed software project. If technical debt is also part of the problem, that dimension is covered here too.
Failed software projects rarely announce themselves cleanly. Most of the time they look like smaller, unrelated problems — until they don't.
A vendor demos against 200 rows. Production has 4.2 million. The system collapses on day one. A logistics company runs eight months of reports before discovering every margin figure was wrong — freight costs calculated against a hard-coded rate table nobody updated since development. A fintech deployment involves 17 manual steps, config files stored in someone's personal Dropbox, and a rollback procedure that has never been tested.
In one engagement, we found a 14-module enterprise platform in which 60% of the business logic resided in a single 8,000-line file. No documentation. No API contracts. A healthcare client's intake system had three live API integrations with no timeout handling and no fallback. One vendor had a 30-second outage. Every active user froze simultaneously.
If any of this sounds familiar, you are not dealing with a delay. You are dealing with a structural failure — and it needs a structural response.
The surface-level explanations — scope creep, missed deadlines, budget overspends — are symptoms, not causes. When an enterprise software partner fails to deliver, the breakdown almost always traces back to one of four structural problems.
Vendors underscope complexity to win contracts, then spend months reconciling what they sold with what the system actually needs. In one case, we found 14 critical architectural issues in a system that had been declared production-ready for 3 months.
Projects stall when ownership is unclear. Requirements shift mid-sprint because too many stakeholders have an opinion and none of them have final authority. IT signs off on deliverables it does not fully understand. Nobody is accountable — until the damage is too visible to ignore.
Hard-coded values, skipped test coverage, and brittle integrations hold together in staging and collapse in production. One financial services client came with a reporting system that passed QA but deadlocked within 90 seconds under real concurrent load.
By the time a project is visibly failing, the relationship has typically been deteriorating for months. Status reports get vague. Issues get reframed as "in progress." The crisis appears sudden — but the warning signs were there all along.
The financial damage extends well beyond what was paid to the first vendor. Real costs include opportunity cost with business processes still running on spreadsheets, data quality risk from partial migrations, internal credibility damage as executive trust in IT erodes, re-procurement costs adding 20 to 30 percent on top of project cost, and regulatory exposure in healthcare and financial services where a failed mid-migration creates real audit risk.
In one engagement, the fully loaded cost of a seven-month delay totaled $2.1M, against an original budget of $900,000. Most organizations do not calculate that number until it is too late.
At this stage, most organizations reach for a structured recovery approach—but not all frameworks succeed in real enterprise conditions.
Companies rush the diagnosis to exhibit effort. Executives want visible movement within two weeks. The team starts fixing things before understanding what is broken. Six months later, the same root cause resurfaces with different symptoms.
They patch the architecture rather than confronting it. In one case, a team spent 4 months adding caching layers and load balancers, achieving only a marginal improvement. The actual problem was a fundamentally incorrect data model. A two-week assessment would have prevented a $340,000 effort aimed at the wrong layer.
They retain the same governance that caused the failure. If the project failed because no single person owned product decisions, launching recovery under the same committee model guarantees the same result. And they repeat the same vendor mistakes — 70% of companies engage a new vendor within 90 days, often without a structured assessment. The new vendor inherits undocumented assumptions, makes new ones, and the cycle continues.
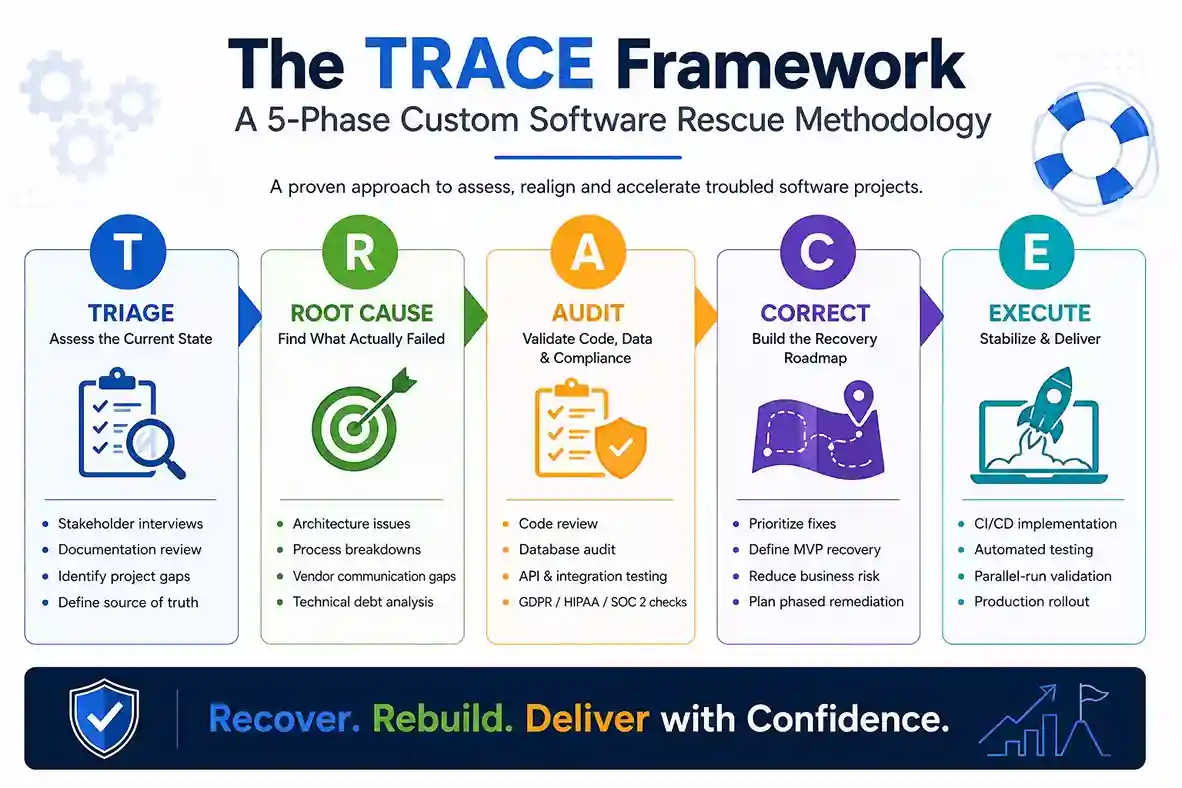
Generic project management does not work for software rescue. The TRACE Framework — Triage, Root Cause, Audit, Correct, Execute — is a forensic, phased process built specifically for this environment.
Before any code is reviewed, the rescue team establishes an unbiased picture of the current state. Independent stakeholder interviews, every piece of project documentation, and a clear catalog of what was promised versus what exists. The output is a source-of-truth document completed within five business days.
Once the facts are on the table, the team digs into why things actually broke. Is it the architecture? The process? The relationship between client and vendor? Every problem gets sorted into one of three buckets — something you can fix without touching the foundation, something that needs structural change, or something that points toward starting over.
The technical side is where hard facts surface. The database gets taken apart — missing indexes, inefficient queries, normalization problems nobody caught because nobody tested with actual data volumes. Every API integration is reviewed to determine what occurs when something goes wrong. Does it time out cleanly? Does it retry? Or does it silently take half the system down?
The business side matters just as much. The team goes back to the earliest signed statement of work and checks every requirement against what was actually built. Business rules get tested from scratch. Data migration gets confirmed with actual record counts, not vendor assurances. The compliance posture is reviewed against GDPR, HIPAA, or SOC 2. See our software testing and QA services for the full standards we apply.
In one case, automated analysis flagged 340 issues. Manual review found 14 critical issues — three were GDPR security vulnerabilities that were invisible in the demo and staging environments. In another engagement, a two-week assessment prevented a six-month rebuild by showing 70% of the core business logic was correct. Only the unification layer needed replacing.
The recovery team builds a remediation roadmap ranked by business impact. A Minimum Viable Recovery milestone gets defined — the smallest working version that delivers something real to the business. The biggest mistake at this stage is trying to fix everything at once. Teams that sequence their fixes carefully move slower at the start and faster by the end.
Remediation runs under a new governance structure. Code reviews are mandatory. Automated testing gates are enforced before anything ships. A parallel-run period validates the fixed system against live operations before cutover. CI/CD pipelines get implemented so future degradation is visible before it becomes a crisis. See our DevOps and CI/CD consulting services for more details on implementation.
If remediation will cost more than 60% of what a disciplined rebuild costs, the case for rescue weakens. A client who skipped this calculation spent $280,000 optimizing a system whose data model made the performance target permanently unreachable.
| Core architecture | Sound but poorly implemented | Fundamentally misaligned with requirements |
| Data model | Salvageable with migration | Corrupted or structurally wrong |
| Code quality | Poor but consistent | Inconsistent, undocumented, untestable |
| Business logic | Mostly implemented | Missing or incorrect throughout |
| Cost ratio | Remediation under 50% of rebuild | Remediation exceeds 60–70% of rebuild |
For larger platforms, add 30- 50% to these periods. Any firm promising full resolution in under six weeks for a system that took 12 months to build is selling a timeline, not a plan. One client was told 30 days. The honest assessment said 22 weeks. Delivered on schedule — because it was planned with accurate information, not optimism.
They have a direct conflict of interest. Always engage an independent enterprise software partner for assessment.
One company bypassed the initial review and spent $280,000 on performance optimizations before discovering the database schema made the performance target architecturally impossible.
If the same organizational dynamics remain — no empowered product owner, requirements by committee — the recovery will stall for exactly the same reasons.
The moment a team feels pressure to just get something out, they cut the same corners the founding team cut. A rescue needs tighter controls and more structured reviews than standard development. Organizations exploring AI-assisted development during recovery should be careful — new technology without governance can add burden to an already fragile system.

Any firm that proposes a rescue without a formal assessment phase is selling remediation before understanding the problem. A credible partner insists on a structured review period before committing to any scope. If they skip this, walk away.
Ask them to walk through exactly how they would review your system — the tools they use and how findings translate into a roadmap. Vague answers here mean vague execution later.
A trustworthy partner delivers findings independently of the remediation proposal. If both arrive in the same document, the assessment was reverse-engineered to justify a predetermined engagement size.
"What is the probability this project can be fixed without a full rebuild?" A confident, evidence-based answer — even an uncomfortable one — is a better sign than a reassuring one.
Taking over a failing custom software project requires technical strictness, organizational honesty, and experienced judgment that most internal IT teams are not built to provide. The TRACE Framework does not guarantee recovery — no methodology does. But it stops the most common failure mode: acting before understanding.
Organizations that achieve a real recovery slow down before they speed up. They put diagnosis ahead of remediation. They make the fix-versus-rebuild call with evidence, not pressure. In one documented engagement, a two-week assessment prevented a six-month rebuild worth $1.4M — and delivered a stable system within the same budget originally allocated.
As of 2026, the enterprise software landscape stays more complex — more integrations, more compliance obligations, more AI components layered on top of legacy systems. The conditions that produce failed projects have not improved. Partnering with a reliable custom software development company for structured recovery is what separates a system that stabilizes from one that quietly accumulates risk until the next crisis.
If your organization is sitting on a stalled, over-budget, or broken custom software project, the question is not whether to act. It is whether you act with a clear-eyed assessment of what you are actually dealing with — or repeat the exact conditions that caused the failure in the first place.
Speak with our recovery specialists to begin with a structured, no-obligation assessment. Most clients have a clear picture of their situation within five business days.